2 TL ; DR - Guide d’évaluation des comparaisons à un groupe contrôle externe
3 Les études de comparaison externe, de quoi s’agit-il ?
5 Les problématiques méthodologiques soulevées par les comparaisons externes
6 Les comparaisons externes sont des études observationnelles
7 Position des agences de régulation et de HTA
8 De la nécessité d’avoir des preuves de l’intérêt cliniques des nouveaux traitements
9 Les sources de données utilisables
10 Les problématiques liées à l’aspect rétrospectif de ces études
12 Démarche hypothético déductive
13 L’inférence causale et les hypothèses sous-jacentes
15 Les techniques d’analyses statistiques
15.1 Les techniques basées sur l’appariement (matching )
15.2.2 Le calcul du score de propension
15.2.3 L’importance du chevauchement des distributions des scores de propension
15.3 L’appariement sur le score de propension
§ Limites de l’appariement sur le score de propension
15.4 Les méthodes de pondération
§ L’effective sample size (ESS)
§ Distribution des poids, hypothèse de positivité
15.4.2 Pondérations non basées sur le score de propension
15.5 La g computation (g formula)
15.6 Les méthodes doubles robustes
15.7 Les méthodes de régression
15.8 Les techniques d e maching learning (IA)
16 Le diagnostic d’absence de biais de confusion résiduel
18 Identifications des patients dans la source de données
21 Les outils d’évaluation du risque de biais
22 L’émulation d’un essai cible
23 Le benchmarking et les contrôles positifs
24 Analyses de sensibilité , analyses quantitatives du biais
26 Contrôle du risque alpha global
Le score de propension peut être utilisé comme variable d’appariement unique. À chaque patient du groupe traité est associé le patient contrôle ayant le score de propension le plus proche de celui du patient (plus proche voisin), ce qui empêche d’avoir des patients impossibles à apparier contrairement à l’appariement sur les covariables elles-mêmes. Cependant cela pourrait conduire à apparier des patients ayant des valeurs de score de propension très différentes. Pour l’éviter, une contrainte est ajoutée n’autorisant l’appariement de 2 patients que si leurs scores ne sont pas trop différents dans une certaine tolérance appelée caliper . Il est donc possible de ne pas pouvoir apparier certains patients, car aucun patient contrôle n’a de score de propension suffisamment proche dans cette tolérance.
L’intérêt de l’appariement sur le score de propension est qu’il permet de constituer deux groupes de sujets comparables sur toutes les variables constituant le score de propension (sauf cas assez exceptionnel). Cette propriété a fait le succès de cette méthode et explique pourquoi elle est largement utilisée même si elle n’est pas optimum et si de meilleures méthodes sont disponibles (pondération). En effet, après appariement (after propensity score matching ), le tableau de description des caractéristiques de baseline des patients montre des valeurs presque identiques entre les 2 groupes appariés pour toutes les variables comprises dans le score de propension. Ce tableau ressemble alors comme à ce qui aurait été obtenu avec un essai randomisé. Les effectifs sont aussi identiques entre les deux groupes si un appariement 1 :1 a été utilisé, de la même façon que dans un essai randomisé. La comparaison à l’essai randomisé s’arrête ici, car, si des facteurs de confusion n’ont pas été pris en compte dans le score de propension, la fiabilité du résultat n’est pas identique à celle d’un essai randomisé où la randomisation prend en compte, automatiquement, tous les facteurs de confusion sans qu’il soit obligé de les identifier et de les mesurer.
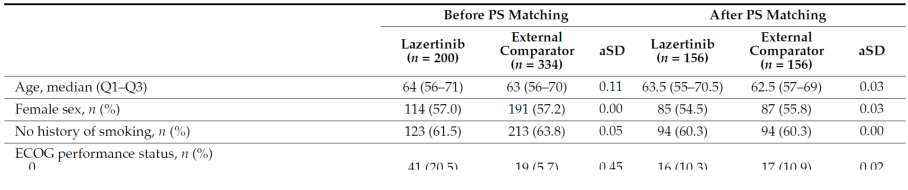
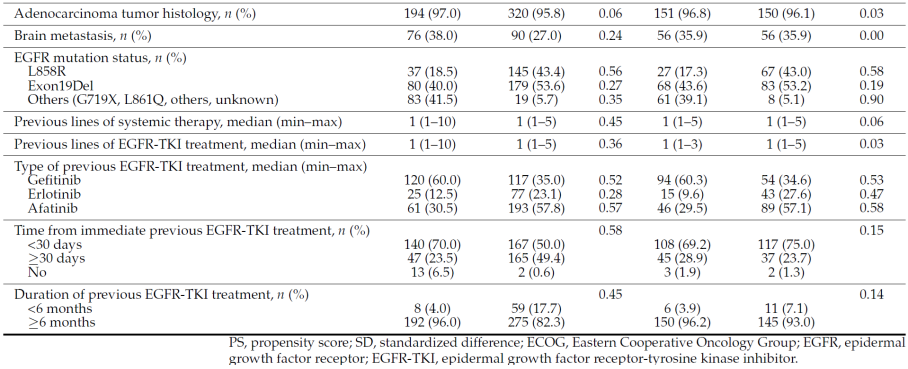
Le tableau de l’exemple encadré ci-dessous illustre cet apport de l’appariement sur le score de propension. Les trois premières colonnes comparent les données du groupe traité et du groupe contrôle avant appariement (before PS matching ). Les trois dernières colonnes rapportent les caractéristiques dans les groupes appariés (after PS matching ).
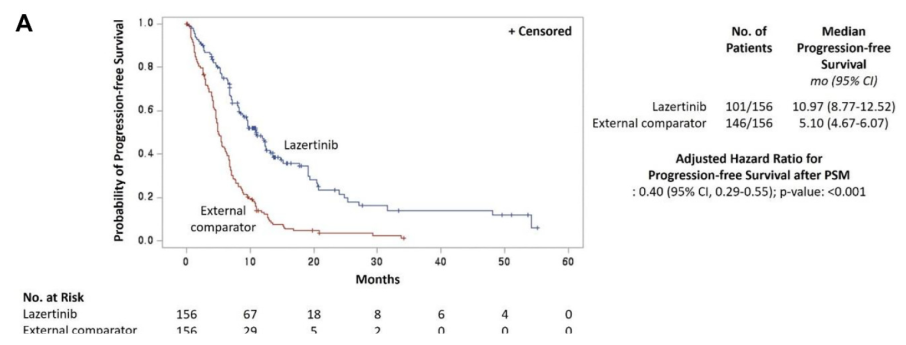
Une étude de comparaison externe compare le lazertinib à une chimiothérapie à base de sels de platine chez des patients avec un cancer du poumon non à petites cellules EGFR positifs après échec des inhibiteurs de l'EGFR [146] . Le groupe traité par lazertinib regroupe initialement 200 patients. Un groupe contrôle externe est réalisé à partir d’une source d données de patients traités par chimiothérapie comprenant 334 patients. Un appariement par score de propension a été utilisé pour corriger les résultats du biais de confusion.
La partie gauche du tableau ci-dessous décrit les caractéristiques des patients de ces 2 groupes (before PS matching).
La partie droite (after PS matching) décrit les deux groupes obtenus par appariement. L’effectif de ces groupes est inférieur à l’effectif initial témoignant que certains patients du groupe traité n’ont pas pu être appariés à des patients contrôles, car aucun patient contrôle n’avait un score de propension suffisamment proche (compte tenu du caliper utilisé).
Les eux groupes appariés sont ensuite comparée de manière classique pour déterminer l’effet du traitement :
Un indice, appelé SMD (standardized mean difference ), permet de mesurer la différence entre les 2 groupes au niveau d’une variable. Cet indice prend des valeurs entre à et 1. Zéro indique que les 2 groupes ont la même valeur sur cette variable. Plus la valeur de SMD est grande, plus il y aune différence importante entre les 2 groupes. Habituellement on considère qu’une valeur supérieure à 0.1 témoigne d’un écart important. Le SMD est parfois exprimé en pourcentage, dans ce cas la valeur seuil est 10% et il peut aussi avoir un signe positif ou négatif indiquant le sens de la différence. Il peut aussi s’appeler aSD (adjusted Standard Difference ) à ne pas confondre avec la SD (standard deviation qui est l’écart type).
Dans l’exemple précédent, la SMD (aSD) avant appariement pour le score ECOG est de 0.45, supérieure au seuil de 0.1 et témoignant ainsi d’une différence notable. Après appariement la différence devient négligeable avec un SMD (aSD) en dessous de 0.10 à 0.02 [147] .
Des p value sont parfois donnée à la place de la SMD. La p value n’a pas beaucoup d’intérêt dans ce cas (manque de puissance, non adapté pour montrer l’absence de différence et valeur dépendant de la taille de l’échantillon) et ne devrait pas être utilisé note n° 19 .
De nombreuses variantes d’appariement par score de propension sont possibles.
Des ratios d’appariement supérieurs à 1 :1 peuvent être utilisées, augmentant la précision, mais exposant à une diminution du contrôle de la confusion et à un manque de transparence [148] [149] [150] .
L’appariement peut être effectué avec ou sans remise. En cas d’appariement avec remise, un patient du groupe contrôle peut-être apparié plusieurs fois avec des patients différents du groupe traité. Cela peut être utile en cas de petits effectifs.
L’appariement peut aussi se faire avec ou sans caliper. Le caliper désigne la tolérance de différence de score de propension acceptable pour apparier deux patients. En pratique, on fixe une valeur seuil (par exemple, 0,2 fois l’écart-type du score de propension) : seuls les patients contrôles dont le score de propension se situe à l’intérieur de cette fenêtre autour du score du patient traité sont éligibles à l’appariement. L’utilisation d’un caliper permet de réduire le risque d’apparier des patients trop différents, améliorant ainsi la comparabilité entre les groupes. Sans caliper, l’appariement se fait avec le plus proche voisin. Cela évite d’avoir des patients non appariés, mais autorise l’appariement de patients ayant des scores de propension très différents.
Il existe aussi des techniques qui ne vont pas travailler patient après patient (greedy matching ), mais qui vont chercher la combinaison globale optimale pour minimiser la somme des différences de score de propension intra-paire (optimal matching).
[19] La SMD mesure une taille d’effet, pas une significativité et ne dépend pas de la taille de l’échantillon
