2 TL ; DR - Guide d’évaluation des comparaisons à un groupe contrôle externe
3 Les études de comparaison externe, de quoi s’agit-il ?
5 Les problématiques méthodologiques soulevées par les comparaisons externes
6 Les comparaisons externes sont des études observationnelles
7 Position des agences de régulation et de HTA
8 De la nécessité d’avoir des preuves de l’intérêt cliniques des nouveaux traitements
9 Les sources de données utilisables
10 Les problématiques liées à l’aspect rétrospectif de ces études
12 Démarche hypothético déductive
13 L’inférence causale et les hypothèses sous-jacentes
14.1 Particularité des facteurs de confusion dans les comparaisons externes
14.1.1 Modificateurs de l’effet du traitement
14.2 La détermination des facteurs de confusion
14.2.2 Revue systématique des facteurs pronostiques
14.3 Les méthodes statistiques
14.4 Les ajustements à éviter car contreproductifs
15 Les techniques d’analyses statistiques
16 Le diagnostic d’absence de biais de confusion résiduel
18 Identifications des patients dans la source de données
21 Les outils d’évaluation du risque de biais
22 L’émulation d’un essai cible
23 Le benchmarking et les contrôles positifs
24 Analyses de sensibilité , analyses quantitatives du biais
26 Contrôle du risque alpha global
Comme dans toute études observationnelles, la finalité de l’analyse des données va être de corriger les résultats du biais de confusion (de supprimer la confusion).
On parle souvent d’analyse ajustée ou d’ajustement sur les facteurs de confusion. Pour les puristes le terme ajustement ne désigne que les méthodes de régression. Comme il existe des d’autres méthodes que les régressions, il conviendrait plutôt de parler d’analyse conditionnelle, ou de prise en compte des facteurs de confusion, ou d’analyse contrôlant les facteurs de confusion.
De nombreuses techniques sont disponible pour effectuer cette correction [134] [135] . Elles fonctionnent toutes correctement lorsque leurs hypothèses fondamentales sont vérifiées. Certaines sont plus robustes (moins sensibles à un écart aux hypothèses) que d’autres, mais en général il est difficile de dire qu’une technique est plus adaptée qu’une autre.
La validité des résultats réside principalement dans la prise en compte de la totalité de facteurs de confusion (cf. section 14.2 ). En effet, si certains facteurs de confusion ne sont pas pris en compte, la méthode, quelle qu’elle soit, y compris une méthode d’IA type machine learning, ne pourra supprimer le biais de confusion induit par ces facteurs oubliés et le résultat sera affecté d’un biais de confusion résiduel.
Comme il est toujours possible que certains facteurs de confusion n’est pas été identifié ou pris en compte, certains estiment qu’il n’est jamais possible de conclure à l’absence de biais de confusion résiduel. C’est par exemple le parti pris par l’outils d’évaluation du risque de biais des ROBINS I (cf. section 21.1).
La section 15 propose une description succincte de des différentes techniques statistiques utilisables pour prendre en compte les facteurs de confusion.
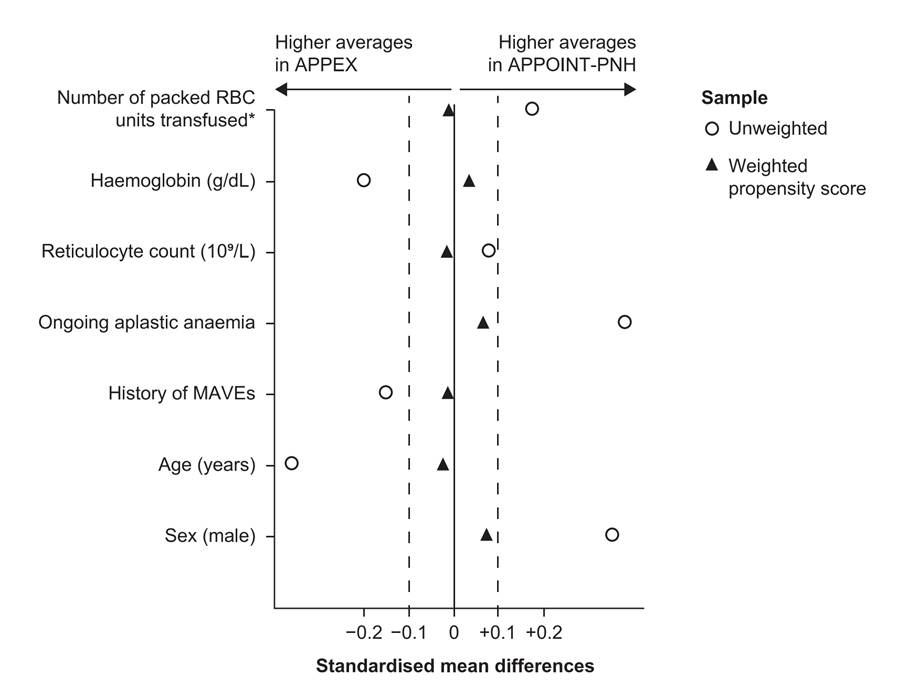 Figure 7 – Exemple de représentation graphique
des SMD avant et après pondération à partir d’un score de propension [136] .
Figure 7 – Exemple de représentation graphique
des SMD avant et après pondération à partir d’un score de propension [136] .
